在 2016 年 3 月由 Google 所開發的人工智慧 Alphago 與人類棋王的世紀大戰,像電影場景般的人機大戰受到全世界的矚目,機器學習頓時成為全世界最火的顯學,電腦似乎無所不能到了幾乎取代人類的存在,有人對於人類的未來感到興奮,也有人感到無助絕望。然而小編認為如何讓電腦學習認知,尚面臨許多實際的問題,像是訓練資料不夠,人工標籤等等。機器要完全取代人類其實還有很長一段路要走。本篇僅介紹、分享小編在學習機器學習方法上的心得,並且使用資料做預測,與統計方法的迴歸分析做比較。
神經元( Neuron )
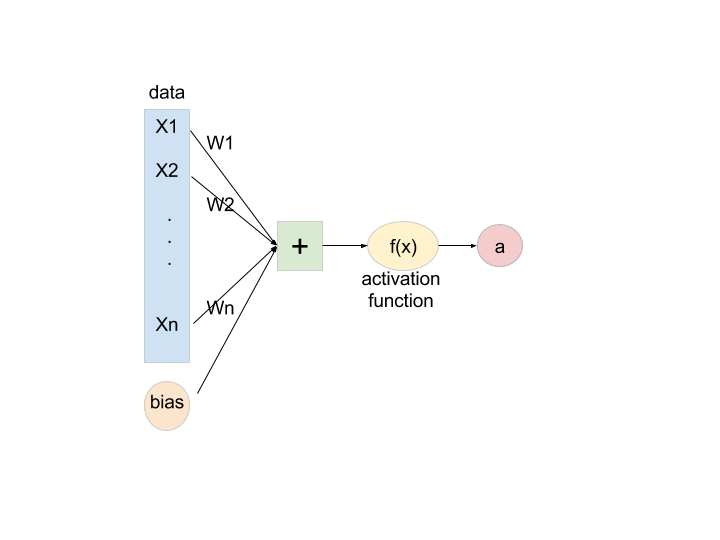
在深度學習的架構中,神經元為一個最小的單位,資料為 

在深度學習或人工智慧中,所謂的神經元一直以來都是使用羅吉斯回歸,而為什麼要使用羅吉斯回歸並非一般的多元線性回歸?這跟所要解決的問題相關。深度學習在最開始被設計為分類器,希望預測產生的值為離散變數,所以大部分的神經元才會採用羅吉斯回歸,而事實上是可以根據不同的問題採用羅吉斯回歸或多元線性回歸。
深度學習 ( Deep learning )
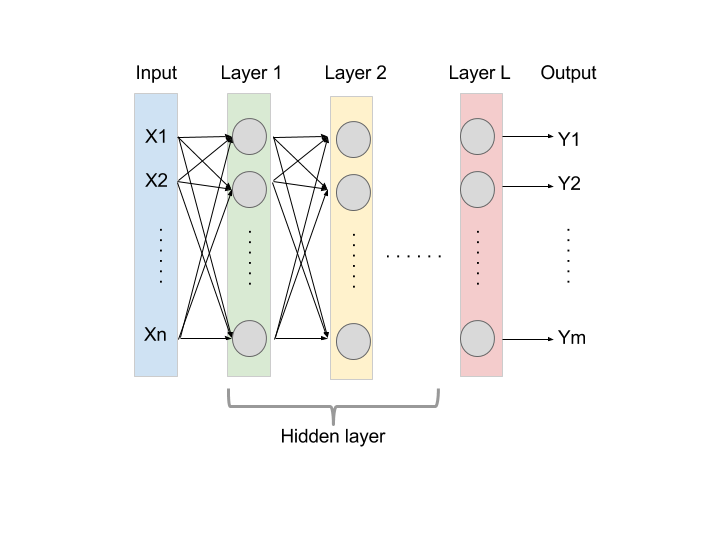
而深度學習架構,則是由多個神經元組成,每個灰色節點為一個神經元所產生的值,隱藏層第一層 ( Layer 1 ) 的值則會成為隱藏層第二層 ( Layer 2 ) 的訓練資料,透過這樣的機制一層一層的傳遞到最後 L 層,m 維度的 L 則是想要知道答案。這樣的架構又稱為類神經網路 ( Neural network )。簡單來說深度學習就是一個大型且超複雜的羅吉斯回歸。
回歸分析 ( Regression analysis)
回歸分析為統計學上預測方法,透過分析變數之間的相關性,建立數學模型來預測變數,當自變數只有一個稱為簡單線性回歸,多個自變數稱為多元線性回歸。

y 為應變數,


統計學的回歸分析的步驟為:
- 判斷資料是否來自常態,沒有的話需要調整。
- 判斷變數是否具有相關性,優先選擇相關性高的變數,並且適時做變數轉換或篩選離群值。
- 檢視模型 R-square ,殘差分析,判斷是否需要調整模型或改用其他模型作為預測。
資料來源
訓練模型使用的資料為 R 套件 mlbench 中的 BostonHousing,資料集為 506 個觀測值及 14 個變數,資料沒有遺失值。在這裡假設想要預測的變數 ( y ) 為 medv ( 自住房屋價格的中位數 )。在這裡挑選間隔 3 筆的資料做為測試資料,也就是序列 1, 4, 7, 10, …, 505 作為測試用資料,其他做為模型訓練資料。
模型預測 — Neural network
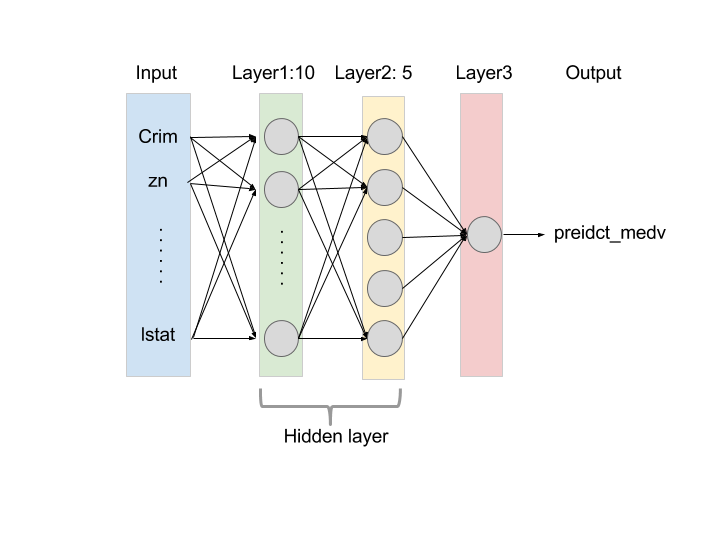
這裡建構兩層的類神經網路為預測模型,第一層有 10 個神經元,第二層有 5 個神經元,第三層則為模型的估計值。第一次訓練次數為 20,000 次,預測測試資料的 R-square 為 0.6466;第二次訓練次數為 200,000 次,預測測試資料的 R-square 為 0.6657。
模型預測 — Regression

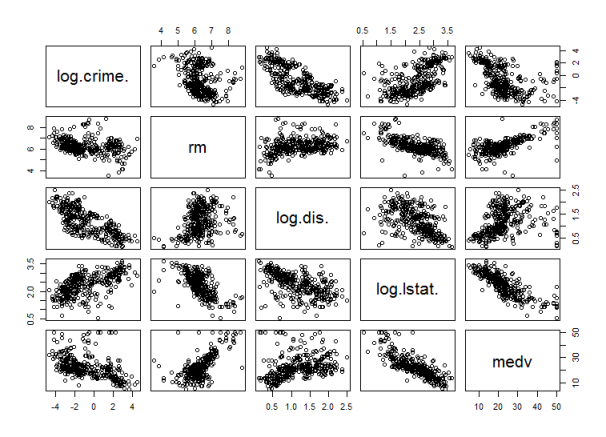
透過散布圖挑選有效變數為 crim, rm, dis, lstat,對變數 crim, dis, lstat 做 natural log 變數轉換。建立回歸模型為 
Call: lm(formula = medv ~ ., data = train2) Residuals: Min 1Q Median 3Q Max -15.8136 -2.7927 -0.6735 2.4126 24.5082 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 32.8626 4.3455 7.562 3.91e-13 *** log.crime. -0.7563 0.1933 -3.913 0.000111 *** rm 2.9089 0.4845 6.004 5.06e-09 *** log.dis. -4.1649 0.7336 -5.677 2.99e-08 *** log.lstat. -10.2557 0.6682 -15.349 < 2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 4.767 on 332 degrees of freedom Multiple R-squared: 0.7214, Adjusted R-squared: 0.7181 F-statistic: 214.9 on 4 and 332 DF, p-value: < 2.2e-16
預測測試資料的 R-square 為 0.716。
結論
深度學習方法提供另一個在建構模型時,快速且方便的預測模型方法,並且可以處理非結構化資料。隨著資料量、訓練次數、模型複雜度的增加提升預測的精準度。然而資料量需要多大才算大?訓練次數最少需要幾次?模型需要多複雜?都還沒有一個評斷的標準。而深度學習方法會出現模型 Overfitting 的情況,也就是雖然模型的 MSE ( Mean square error ) 很小,但是預測實際未知的資料,會有精準度大幅下降的情況,這是在使用上更需要注意的地方。
與深度學習方法相比,回歸分析在建構模型上較嚴謹,且符合直覺,需要計算時間較短,隨著分析者對該領域的知識了解,挑選有效的變數、對變數處理的細膩程度,都會使得模型的精準度會有更好的表現。但是回歸模型有許多條件假設,並且只能處理結構化資料,這也是其不夠全面的缺點之一。
最後小編在這篇只是粗略的使用兩個方法建構模型,不論是深度學習或回歸分析,在建構模型上都是相當熱門同時也是很好的方法。在建構模型前應該先了解自己的資料類型,以及想解決的問題,選擇適當的方法才是上策。

您好,使用類神經網路的方式,是不是無法寫出像回歸分析一樣的方程式呢?
讚讚
可以將類神經網路理解為一大堆羅吉斯回歸的組成,一個 neuron 就是一個羅吉斯回歸,而羅吉斯回歸的結果又會成為下一個羅吉斯回歸的變數,如此傳遞下去。理論上來說是可以寫成方程式,只是參數代表的意義在越深層的神經元越難以理解。
讚讚
為什麼你最後會挑選有效變數為 crim, rm, dis, lstat來放入你的預測模型中,你的挑選標準與原因是什麼呢?
讚讚
你最後挑選有效變數為 crim, rm, dis, lstat,你挑選的標準與原因是什麼呢?
讚讚
在迴歸模型的變數挑選上依照經驗法則,變數的處理也是。
讚讚